清華新聞網(wǎng)2月27日電 醫(yī)學(xué)影像技術(shù)為醫(yī)生提供了疾病診斷的重要原材料,是癌癥、腫瘤等分期評估與分期治療的重要依據(jù)。然而,醫(yī)學(xué)影像通常在成像空間分辨率、時(shí)間分辨率、成像范圍(波長范圍、深度、廣度)、激光劑量(靈敏度)以及對生物組織的損傷之間存在著權(quán)衡。近年來,人工智能的介入允許研究人員在成像過程中犧牲某些指標(biāo)來加強(qiáng)其他指標(biāo),對于成像結(jié)果采用深度學(xué)習(xí)的方法提升被犧牲的指標(biāo),從而優(yōu)化整體性能。例如利用光聲成像技術(shù)(photoacoustic)進(jìn)行人體血管造影,原始空間分辨率為13um*13um*120um(長*寬*高)時(shí),時(shí)間分辨率為4秒/幀。這樣的時(shí)間分辨率無法支持實(shí)時(shí)的組織體動態(tài)監(jiān)測。針對這一困境,可以通過降低成像的空間分辨率來提高時(shí)間分辨率,從而加速成像,即通過t倍欠采樣,將時(shí)間分辨率提高t2倍。隨后對低空間分辨率的成像結(jié)果進(jìn)行基于深度學(xué)習(xí)的空間超分辨,來恢復(fù)欠采樣導(dǎo)致退化的光聲成像,進(jìn)而得到時(shí)空分辨率均較高的結(jié)果。為此,需訓(xùn)練一個(gè)有效的超分辨模型來恢復(fù)空間分辨率。在醫(yī)學(xué)影像中,超分辨模型通常面臨著兩個(gè)主要瓶頸,模型容量和數(shù)據(jù)容量。前者可以通過增加模型參數(shù)、改進(jìn)算法來解決;而后者卻困難重重,由于成像過程復(fù)雜、樣本準(zhǔn)備困難、醫(yī)學(xué)的倫理限制和樣本個(gè)體之間差異較大,很難獲得足夠數(shù)量的血管造影圖像來有效地訓(xùn)練超分辨率神經(jīng)網(wǎng)絡(luò)。
為了應(yīng)對這些挑戰(zhàn),清華大學(xué)深圳國際研究生院數(shù)據(jù)與信息研究院、清華-伯克利深圳學(xué)院關(guān)迅助理教授團(tuán)隊(duì)提出了一種名為DOVE(Doodled Vessel Enhancement)涂鴉血管數(shù)據(jù)集增強(qiáng)的方法,利用手繪的涂鴉訓(xùn)練光聲血管造影超分辨率模型(圖1為原理圖)。該研究基于僅包含32張真實(shí)光聲血管造影圖像的訓(xùn)練數(shù)據(jù)集,首先構(gòu)建一個(gè)擴(kuò)散模型,將手繪涂鴉轉(zhuǎn)換為具有極高真實(shí)度的血管圖像;隨后,利用圖像聚類的方法(圖2)篩選出優(yōu)質(zhì)的生成圖像(圖3);進(jìn)而利用這些圖像訓(xùn)練基于自相似性的超分辨模型。結(jié)果顯示,即使在不同成像條件下收集的光聲血管造影測試集上測試,這種基于生成圖像的訓(xùn)練的模型也能恢復(fù)相對于原始分辨率0.8591均值的結(jié)構(gòu)相似度(SSIM),超過了使用真實(shí)高分辨率圖像訓(xùn)練的模型得分。
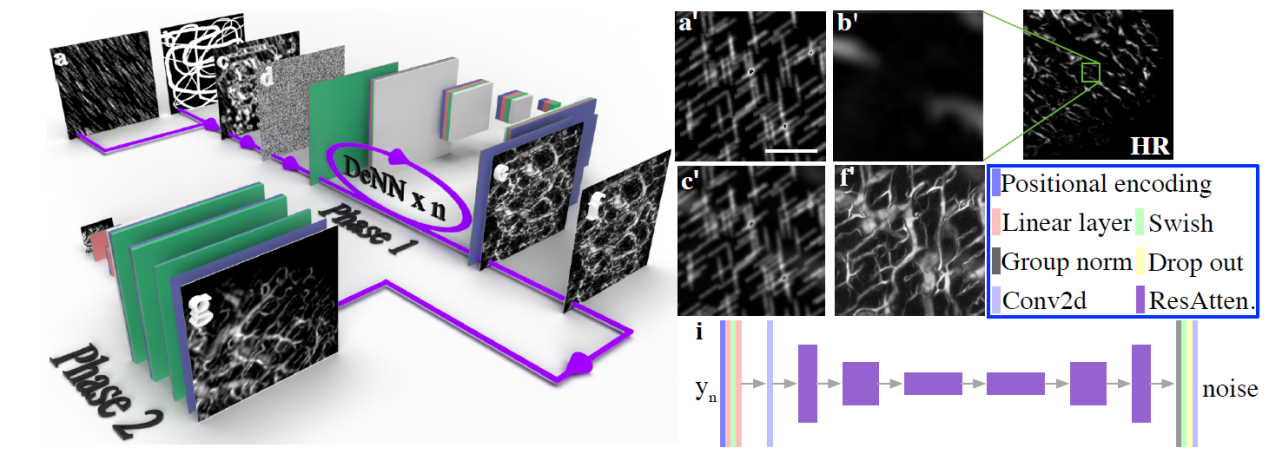
圖1.(a)-(g)為DOVE的示意圖,即利用手繪涂鴉生成的血管造影圖像進(jìn)行超分辨模型的訓(xùn)練。(a)為類似雨的噪聲圖像。(b)為手繪的涂鴉圖像。(c)為(b)與(a)的重疊。(d)為歸一化的高斯噪聲圖像。(e)為從(c)生成的光聲血管造影圖像。(f)為歸一化的光聲血管造影圖像。(g)為重建的超分辨率圖像。(a’)-(f’)對應(yīng)左側(cè)DOVE示意圖的(a)-(f)。(a’)為類似雨的噪聲圖像。(b’)為高分辨率光聲血管造影圖像的隨機(jī)截取圖像。(c’)為(b’)與(a’)的疊加。(f’)為生成模型借助(c’)為輸入而生成的光聲血管造影圖像。(i)為基于UNet的DeNN的結(jié)構(gòu)
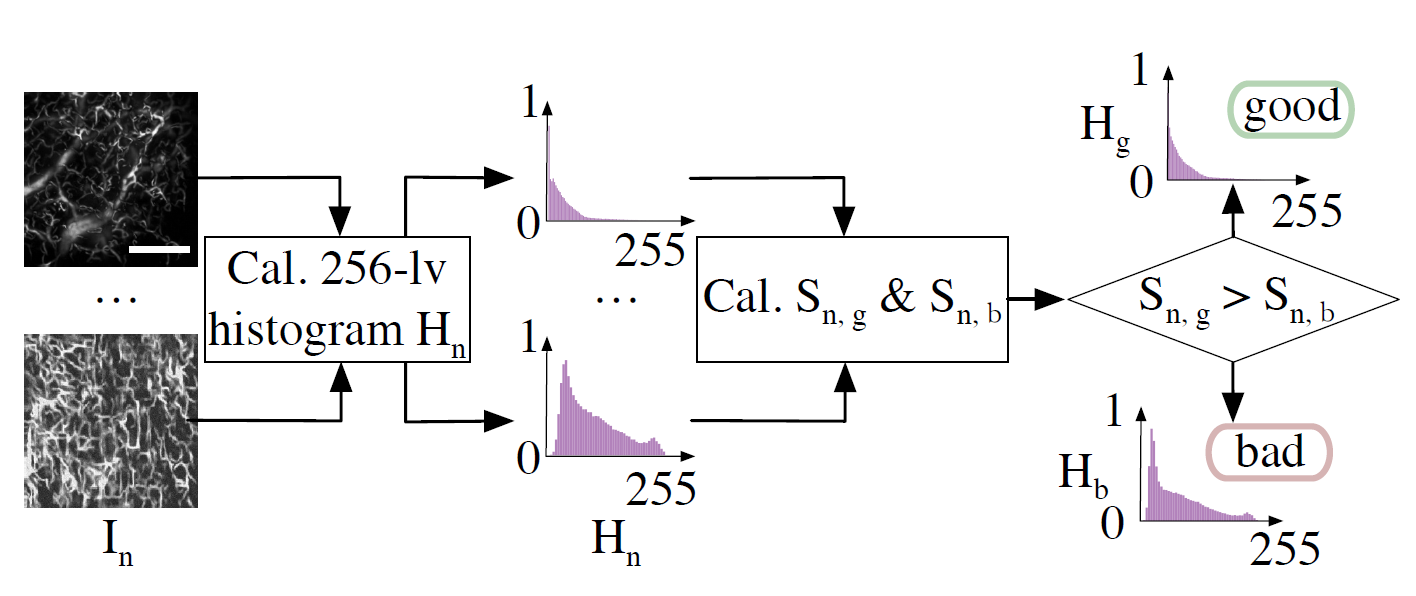
圖2.借助優(yōu)質(zhì)的生成血管造影圖像擁有類似的灰度直方圖分布,研究人員利用聚類刷選優(yōu)質(zhì)的生成圖像,并返回給超分辨模型,用于改善訓(xùn)練精度

圖3.借助噪音圖像生成血管造影圖像的舉例。圖中噪音圖像Noise images輸入不同的生成模型M1,M2以及M3,生成不同的血管造影圖像
這種借助生成模型訓(xùn)練其他模型的方法并不局限于醫(yī)學(xué)影像,也可應(yīng)用于其他小樣本訓(xùn)練場景,從而為小樣本的超分辨模型提供了新思路。同時(shí),該研究顯示,未來人工智能的訓(xùn)練可能會采用更加高效的方式開展,即人工智能模型借助生成模型,實(shí)現(xiàn)“自訓(xùn)練”。研究進(jìn)一步提出,在深度學(xué)習(xí)中提供大量數(shù)據(jù)集“只是通過控制數(shù)據(jù)集來實(shí)現(xiàn)對人工智能模型訓(xùn)練的監(jiān)督,而不是讓人工智能模型真正了解現(xiàn)實(shí)世界的邏輯”,從而對傳統(tǒng)深度學(xué)習(xí)中基于大量采集數(shù)據(jù)來訓(xùn)練優(yōu)質(zhì)模型這一傳統(tǒng)思路和范式提出了挑戰(zhàn)。
近日,該研究以“光聲音血管造影術(shù)的超分辨率的涂鴉血管數(shù)據(jù)集增強(qiáng)方法”(Doodled vessel enhancement for photoacoustic angiography super resolution)為題,發(fā)表于人工智能與醫(yī)學(xué)影像刊物《醫(yī)學(xué)影像分析》(Medical Image Analysis)。
清華大學(xué)深圳國際研究生院數(shù)據(jù)與信息研究院、清華-伯克利深圳學(xué)院2022級博士生馬遠(yuǎn)征為論文的第一作者,關(guān)迅為論文的通訊作者。論文的共同作者還包括西安電子科技大學(xué)副教授周王婷、華南師范大學(xué)教授楊思華,以及清華大學(xué)深圳國際研究生院數(shù)據(jù)和信息研究院、清華-伯克利深圳學(xué)院教授張曉平和助理教授唐彥嵩。該研究得到國家重點(diǎn)研發(fā)計(jì)劃、廣東省自然科學(xué)基金、廣州市科技計(jì)劃項(xiàng)目和深圳市自然科學(xué)基金科研經(jīng)費(fèi)的支持。
論文鏈接:
https://www.sciencedirect.com/science/article/pii/S1361841524000318
供稿:深圳國際研究生院
題圖設(shè)計(jì):李娜
編輯:李華山
審核:郭玲