清華新聞網(wǎng)6月12日電 近年來,人工智能領(lǐng)域在大模型方面取得了顯著進(jìn)展,這些模型通過預(yù)訓(xùn)練的方式從大規(guī)模、多來源的數(shù)據(jù)中提取深層次規(guī)律,進(jìn)而能夠作為“基礎(chǔ)模型”服務(wù)領(lǐng)域的多樣化任務(wù)。例如,語言大模型通過學(xué)習(xí)大量文本數(shù)據(jù),掌握了理解和識別語言的能力,引領(lǐng)了自然語言處理領(lǐng)域的新一輪革命。類似地,生命科學(xué)中的細(xì)胞的DNA序列、基因表達(dá)等屬性也可以被視為一種細(xì)胞“語言”,如果能夠基于這種細(xì)胞“語言”開發(fā)人工智能細(xì)胞大模型,將有望為生命科學(xué)和醫(yī)學(xué)研究提供全新研究范式和革命性研究工具。
清華大學(xué)自動化系生命基礎(chǔ)模型實(shí)驗(yàn)室主任張學(xué)工教授、電子系/AIR馬劍竹教授和百圖生科宋樂博士合作,建立了一個名為scFoundation的細(xì)胞大模型。該模型基于5000萬個細(xì)胞的基因表達(dá)數(shù)據(jù)進(jìn)行訓(xùn)練,擁有1億參數(shù),能夠同時處理約20000個基因。作為基礎(chǔ)模型,它在“虛擬藥物試驗(yàn)”等多種生物醫(yī)學(xué)下游任務(wù)中表現(xiàn)出卓越的性能提升,提供了人工智能在單細(xì)胞研究中的新范式(圖1)。研究成果于2023年5月完成,2024年6月6日以“單細(xì)胞轉(zhuǎn)錄組大規(guī)模基礎(chǔ)模型”(Large-scale foundation model on single-cell transcriptomics)為題,發(fā)表于《自然·方法》(Nature Methods)上。
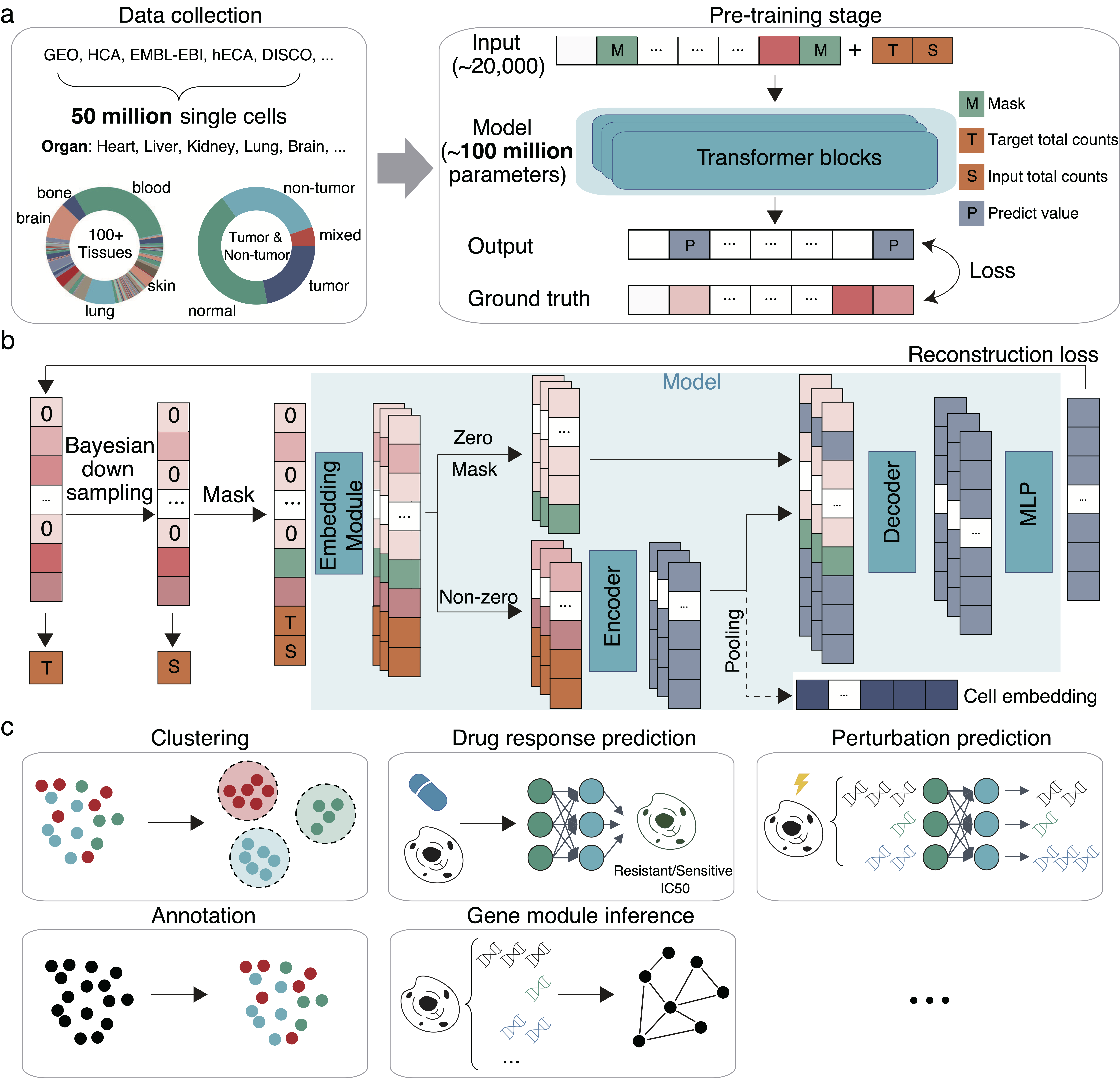
圖1.scFoundation模型及下游應(yīng)用場景
細(xì)胞“語言”與自然語言不同,存在著特征高維度、取值連續(xù)且稀疏等難點(diǎn)。為此,研究團(tuán)隊(duì)針對性設(shè)計(jì)模型架構(gòu),使scFoundation的值編碼模塊可直接將連續(xù)的基因表達(dá)值轉(zhuǎn)化為向量,并通過設(shè)計(jì)一個基于Transformer的非對稱模型架構(gòu),在保持參數(shù)規(guī)模不變的同時幅提高了計(jì)算效率。此外,考慮到單細(xì)胞數(shù)據(jù)質(zhì)量存在明顯差異的特點(diǎn),研究團(tuán)隊(duì)還設(shè)計(jì)了一種由低質(zhì)量數(shù)據(jù)恢復(fù)高質(zhì)量數(shù)據(jù)的預(yù)訓(xùn)練任務(wù),進(jìn)一步增強(qiáng)了預(yù)訓(xùn)練模型對不同來源下游數(shù)據(jù)的適應(yīng)能力。
在實(shí)際應(yīng)用中,scFoundation模型支持“開箱即用”和“微調(diào)”兩種模式。在“開箱即用”模式下,得益于其獨(dú)特的預(yù)訓(xùn)練任務(wù),該模型能直接用于提升細(xì)胞數(shù)據(jù)的質(zhì)量,在不需要進(jìn)一步調(diào)整的情況下便可達(dá)到或超越現(xiàn)有方法的效果。此外,用戶可以利用scFoundation提取細(xì)胞的預(yù)訓(xùn)練表征,該表征可以用于識別細(xì)胞類型特異基因模塊和轉(zhuǎn)錄因子,并可廣泛應(yīng)用于“虛擬藥物試驗(yàn)”等下游任務(wù)中。實(shí)驗(yàn)測試結(jié)果表明,利用scFoundation模型可以顯著提升細(xì)胞癌癥藥物反應(yīng)、細(xì)胞擾動實(shí)驗(yàn)等任務(wù)的性能。在“微調(diào)”模式下,scFoundation在細(xì)胞類型標(biāo)注等任務(wù)上的表現(xiàn)遠(yuǎn)超傳統(tǒng)方法。研究團(tuán)隊(duì)通過多項(xiàng)實(shí)驗(yàn)分析了模型中不同模塊設(shè)計(jì)對性能的具體影響,相關(guān)模型細(xì)節(jié)已在NeurIPS2024的xTrimoGene模型文章中發(fā)表。目前模型權(quán)重及代碼已開源,同時也提供了模型API供在線輕量使用。
綜上所述,scFoundation模型為生命科學(xué)基礎(chǔ)研究、細(xì)胞擾動響應(yīng)預(yù)測、藥物靶點(diǎn)發(fā)現(xiàn)等領(lǐng)域提供了創(chuàng)新方法工具,并在模型架構(gòu)、訓(xùn)練框架和下游示范應(yīng)用體系等方面為細(xì)胞大模型研究提供了新的思路和方法,成功地拓展了單細(xì)胞領(lǐng)域基礎(chǔ)模型的邊界,為開展數(shù)基空間中的虛擬藥物實(shí)驗(yàn)等未來研究奠定了基礎(chǔ)。
張學(xué)工、馬劍竹、宋樂為論文通訊作者。清華大學(xué)自動化系2021級博士生郝敏升為論文第一作者。
論文鏈接:
https://www.nature.com/articles/s41592-024-02305-7
供稿:自動化系
題圖設(shè)計(jì):韓羽臻
編輯:李華山
審核:郭玲